Edge AI vs Cloud AI: The Debate Is Real
As LLMs become central to everything from smart assistants to CI/CD workflows, one major question keeps coming up:
Should we deploy LLMs at the edge (local inference) or rely on powerful cloud APIs?
We’ve now deployed both models in production across developer tooling, observability systems, and private search products. This article explores the real-world trade-offs, costs, and architectural challenges in deploying AI at the edge vs in the cloud.
We’ll include:
Real latency & cost benchmarks
Tooling & infrastructure setups
GitHub + Hugging Face project references
Links to further reading on Cerebrix
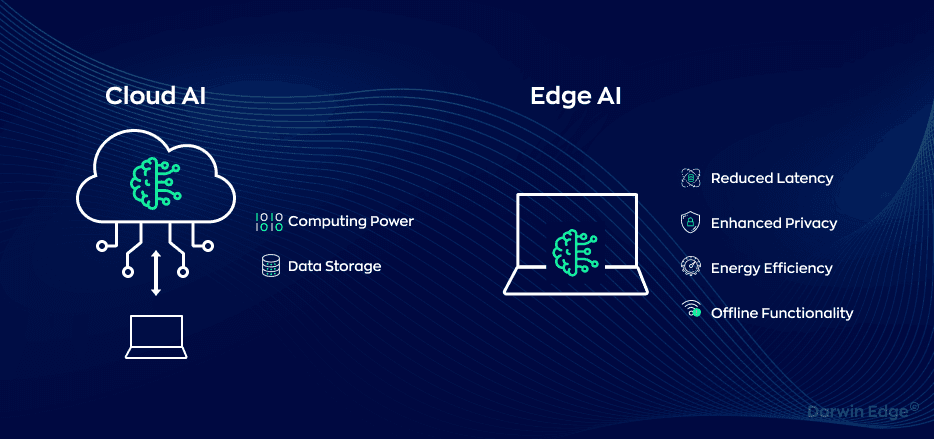
Edge AI: Running LLMs Locally or at the Device Level
Definition:
Edge AI refers to running LLM inference on local hardware — laptops, phones, or edge servers — without a call to a centralized cloud model.
Tools:
llama.cpp — blazing fast inference in C++ for LLaMA models
mlc-llm — optimized local inference on WebGPU, Android, iOS
Ollama — install and serve models like LLaMA, Mistral locally via simple CLI
PrivateGPT — local question-answering over your documents
Pros:
Ultra-low latency (<100ms) on-device
Full data privacy: nothing leaves your machine
Ideal for offline or air-gapped deployments
Zero token-based billing
Cons:
Limited context window (4k–8k tokens on small models)
Heavier setup (quantization, dependency management)
Slower performance vs cloud-hosted GPT-4/Claude 3 on complex tasks
Requires local GPU or Apple Silicon for best speeds
Benchmark: Ollama + Mistral 7B on Mac M2 Pro
Cloud AI: Centralized Inference via API
Definition:
Cloud AI uses hosted services like OpenAI, Anthropic, or Azure OpenAI to serve LLM responses over REST APIs.
Providers:
OpenAI — GPT-4, GPT-3.5 APIs
Anthropic — Claude 3
Azure OpenAI — Microsoft-hosted GPT access
Pros:
Access to cutting-edge models (GPT-4o, Claude 3, etc.)
High throughput + long context (32k+ tokens)
No infra or dependency setup
Easy scalability + enterprise SLAs
Cons:
Network latency (200–500ms)
Cost per token adds up fast
Data privacy concerns for regulated workloads
Subject to rate limiting and regional outages
Benchmark: GPT-4o via OpenAI API
Architectural Trade-offs
Latency Comparison:
Scenario | Edge AI (Ollama) | Cloud AI (GPT-4 API) |
|---|---|---|
Local inference (M2 chip) | ~80ms/token | - |
Remote API call | - | ~400ms total latency |
Offline availability | ✅ | ❌ |
Cost Comparison (Monthly @ 1M tokens):
Model | Edge AI (Mistral via Ollama) | Cloud AI (GPT-4o) |
Infra | $0 (on-device) | N/A |
API cost | $0 | ~$50–$80/month |
Privacy | 100% local | Shared infra |
Use Cases: When to Use Which
Use Edge AI if:
You need full privacy or offline access (e.g., field operations, military)
You control the hardware (e.g., custom app on MacBooks, Jetson devices)
You want to avoid recurring API bills
Use Cloud AI if:
You need top-tier model accuracy (GPT-4, Claude 3)
Your context size requirements >16k tokens
You need zero-maintenance managed infra
You require scalable, multi-user SaaS delivery
Best Practice Architectures
Hybrid AI Gateway Pattern
Try edge model first (fast, cheap, private)
Fallback to cloud if:
Confidence is low
Context exceeds limit
Task is beyond local model
This "local-first, cloud-optional" model is used by projects like LM Studio and PrivateGPT
Tooling Support
LangChain for routing logic
PromptLayer for logging + traceability
HuggingFace Transformers for seamless switching between local and cloud models
Further Reading & Resources
Cerebrix Articles:
YouTube: Two Minute Papers (great breakdowns of edge model trends)
Final Takeaway: It’s Not Either/Or
Edge AI and Cloud AI aren’t enemies. They’re two sides of a deployment spectrum.
Cloud is power and ease
Edge is privacy and control
If you want best-in-class LLM infrastructure, build for interoperability, fallbacks, and multi-modal inference paths.
Your AI doesn't need to live in one place. It needs to live where it works best.
Want to see how we integrated both into our LLM-powered DevOps agent? Head to Cerebrix for technical deep dives and real production architectures.
NEVER MISS A THING!
Subscribe and get freshly baked articles. Join the community!
Join the newsletter to receive the latest updates in your inbox.