Why Self‑Healing Matters
A “job queue” isn’t just about pushing tasks and processing them—it’s about reliability:
Tasks fail randomly or persist too long
Workers disconnect
Redis may drop jobs
Event backlogs grow unnoticed
A self-healing queue automatically repairs these faults, ensuring continuous processing without manual intervention.
BullMQ in Production
BullMQ, the modern successor to Bull, provides robust queues, retries, delayed jobs, prioritization, and Redis-based persistence—all designed with failure handling in mind cs.linux-console.net.
The official BullMQ docs highlight these production considerations docs.bullmq.io:
Enable Redis persistence (AOF, noeviction policy)
Auto-reconnect on connection loss
Graceful worker shutdown
Configure backoff strategies and retries
Implement job cleanup policies
Core Blueprint: Queue + Scheduler + Worker
Features enabled:
QueueScheduler reactivates stalled jobs
Retries via job options (backoff + attempts)
Events to monitor failures, restarts, and drain
Auto-reconnect with resilient Redis settings medium.com
Implementing Self‑Healing
1. Auto‑retry on Failures
✅ Automatic retries with exponential backoff
✅ Automatically removes stale jobs after 1 hour
2. Catch Unhandled Rejections
Visibility & Monitoring
Community engineers on Reddit emphasize queue observability:
“Add visibility around queues… catching stuck workers or job backlogs before users notice” reddit.com.
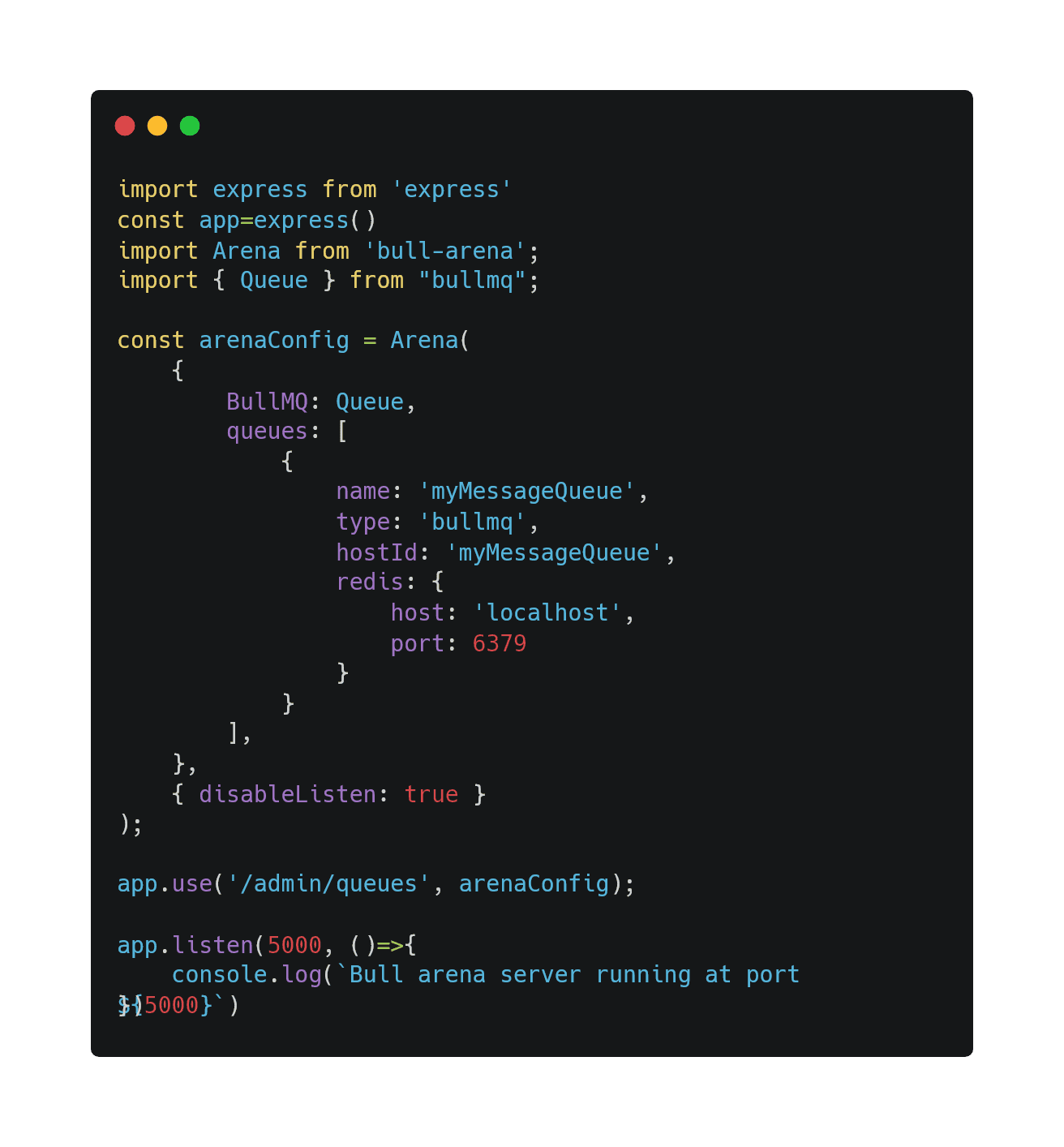
Use libraries like BullBoard or custom dashboards, and monitor:
Age of oldest job
Rate of failed/retried jobs
Number of stalled jobs
Worker heartbeat health
Real-World Resilience Stories
Rakesh Sankar describes building fault-tolerant QueueClusters, including Redis clusters, high concurrency, retry logic, and operational safeguards reddit.com.
Key lessons:
Deploy Redis with AOF enabled
Use
noevictionRedis policyCluster multiple workers for redundancy
Graceful shutdown to prevent job duplication
Production Checklist
|
Self‑Healing Flow in Practice
Producer adds job with retry policy
QueueScheduler detects stalled jobs
Worker processes job; retries on failure
QueueEvents logs and monitors job health
Admin dashboard surfaces issues
Auto-cleanup of old job metadata
Add external alerts (e.g. Slack) on failure thresholds and integrate DLQ if needed for manual inspection.
Alternative Patterns
While BullMQ is excellent, some teams choose Postgres‑backed alternatives like Hatchet for stronger transactional guarantees reddit.com. Still, BullMQ provides unparalleled performance and features for Redis-based production workloads dragonflydb.io.
Final Take
BullMQ delivers a resilient, feature-rich foundation for self-healing job queues. When you pair it with Redis best practices, retries, observability, and robust worker logic, you create a system that maintains itself—and alerts you when manual intervention is needed.
NEVER MISS A THING!
Subscribe and get freshly baked articles. Join the community!
Join the newsletter to receive the latest updates in your inbox.